Задачи сегментации изображения с помощью нейронной сети Unet
Сегментация изображений с U-Net на практике
Введение
В этом блог посте мы посмотрим как Unet работает, как реализовать его, и какие данные нужны для его обучения. Для этого мы будем рассматривать:
- Оригинальную статью Unet как источник для вдохновения.
- Pytorch как инструмент для реализации нашей задумки.
- Kaggle соревнования как место где мы можем опробовать наши гипотезы на реальных данных.
Мы не будем следовать на 100% за статьей, но мы постараемся реализовать ее суть, адаптировать под наши нужды.
Презентация проблемы
В этой задаче нам дано изображение машины и его бинарная маска(локализующая положение машины на изображении). Мы хотим создать модель, которая будет будет способна отделять изображение машины от фона с попиксельной точностью более 99%.
Для понимания того что мы хотим, gif изображение ниже:
Изображение слева - это исходное изображение, справа - маска, которая будет применяться на изображение. Мы будем использовать Unet нейронную сеть, которая будет учиться автоматически создавать маску.
- Подавая в нейронную сеть изображения автомобилей.
- Используя функцию потерь, сравнивая вывод нейронной сети с соответствующими масками и возвращающую ошибку для сети, чтобы узнать в каких местах сеть ошибается.
Структура кода
Код был максимально упрощен для понимания как это работает. Основной код находится в этом файле main.py, разберем его построчно.
Код
Мы будем итеративно проходить через код в main.py и через статью. Не волнуйтесь о деталях, спрятанных в других файлах проекта: нужные мы продемонстрируем по мере необходимости.
Давайте начнем с начала:
def main():
# Hyperparameters
input_img_resize = (572, 572) # The resize size of the input images of the neural net
output_img_resize = (388, 388) # The resize size of the output images of the neural net
batch_size =3
epochs =50
threshold =0.5
validation_size =0.2
sample_size = None
# -- Optional parameters
threads = cpu_count()
use_cuda = torch.cuda.is_available()
script_dir = os.path.dirname(os.path.abspath(__file__))
# Training callbacks
tb_viz_cb = TensorboardVisualizerCallback(os.path.join(script_dir,'../logs/tb_viz'))
tb_logs_cb = TensorboardLoggerCallback(os.path.join(script_dir,'../logs/tb_logs'))
model_saver_cb = ModelSaverCallback(os.path.join(script_dir,'../output/models/model_' + helpers.get_model_timestamp()), verbose=True)
В первом разделе вы определяете свои гиперпараметры, их можете настроить по своему усмотрению, например в зависимости от вашей памяти GPU. Optimal parametes определяют некоторые полезные параметры и callbacks. TensorboardVisualizerCallback - это класс, который будет сохранять предсказания в tensorboard в каждую эпоху тренировочного процесса, TensorboardLoggerCallback сохранит значения функций потерь и попиксельную «точность» в tensorboard. И наконец ModelSaverCallback сохранит вашу модель после завершения обучения.
# Download the datasets ds_fetcher = DatasetFetcher() ds_fetcher.download_dataset()
Этот раздел автоматически загружает и извлекает набор данных из Kaggle. Обратите внимание, что для успешной работы этого участка кода вам необходимо иметь учетную запись Kaggle с логином и паролем, которые должны быть помещены в переменные окружения KAGGLE_USER и KAGGLE_PASSWD перед запуском скрипта. Также требуется принять правила конкурса, перед загрузкой данных. Это можно сделать на вкладке загрузки данных конкурса
# Get the path to the files for the neural net X_train, y_train, X_valid, y_valid = ds_fetcher.get_train_files(sample_size=sample_size, validation_size=validation_size) full_x_test = ds_fetcher.get_test_files(sample_size)
Тут мы просто разделили train set на тренировочную и валидационную выборку, далее загрузили тестовый датасет (у которого мы не имеем масок, и на котором нужно предсказывать маски для проверки на public и private leaderboard на kaggle).
# Testing callbacks pred_saver_cb = PredictionsSaverCallback(os.path.join(script_dir,'../output/submit.csv.gz'), origin_img_size, threshold)
Эта строка определяет callback функцию для теста (или предсказания). Она будет сохранять предсказания в файле gzip каждый раз, когда будет произведена новая партия предсказания. Таким образом, предсказания не будут сохранятся в памяти, так как они очень большие по размеру.
После окончания процесса предсказания вы можете отправить полученный файл submit.csv.gz из выходной папки в Kaggle.
# -- Define our neural net architecture # The original paper has 1 input channel, in our case we have 3 (RGB) net = unet_origin.UNetOriginal((3, *img_resize)) classifier = nn.classifier.CarvanaClassifier(net, epochs) optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.99) train_ds = TrainImageDataset(X_train, y_train, input_img_resize, output_img_resize, X_transform=aug.augment_img) train_loader = DataLoader(train_ds, batch_size, sampler=RandomSampler(train_ds), num_workers=threads, pin_memory=use_cuda) valid_ds = TrainImageDataset(X_valid, y_valid, input_img_resize, output_img_resize, threshold=threshold) valid_loader = DataLoader(valid_ds, batch_size, sampler=SequentialSampler(valid_ds), num_workers=threads, pin_memory=use_cuda)
Здесь мы определяем нашу сеть net и оптимизатор optimizer (подробнее об этом позже), затем создали загрузчик, как для train set, так и для validation set, который будет загружать данные в виде batches.
print("Training on {} samples and validating on {} samples " .format(len(train_loader.dataset), len(valid_loader.dataset))) # Train the classifier classifier.train(train_loader, valid_loader, epochs, callbacks=[tb_viz_cb, tb_logs_cb, model_saver_cb])
Теперь мы запускаем тренировку модели, запуская train и validation loader и callback, который мы определили. Ниже мы рассмотрим некоторые детали реализации этого метода.
test_ds = TestImageDataset(full_x_test, img_resize) test_loader = DataLoader(test_ds, batch_size, sampler=SequentialSampler(test_ds), num_workers=threads, pin_memory=use_cuda) # Predict & save classifier.predict(test_loader, callbacks=[pred_saver_cb]) pred_saver_cb.close_saver()
Наконец, мы делаем то же самое, что и выше, но для прогона предсказания. Мы вызываем наш pred_saver_cb.close_saver(), чтобы очистить и закрыть файл, который содержит предсказания.
Реализация архитектуры нейронной сети
Статья Unet представляет подход для сегментации медицинских изображений. Однако оказывается этот подход также можно использовать и для других задач сегментации. В том числе и для той, над которой мы сейчас будем работать.
Перед тем, как идти вперед, вы должны прочитать статью полностью хотя бы один раз. Не волнуйтесь, если вы не получили полного понимания математического аппарата, вы можете пропустить этот раздел, также как главу «Эксперименты». Наша цель заключается в получении общей картины.
Задача оригинальной статьи отличается от нашей, нам нужно будет адаптировать некоторые части соответственно нашим потребностям.
В то время, когда была написана работа, были пропущены 2 вещи, которые сейчас необходимы для ускорения сходимости нейронной сети:
- BatchNorm.
- Мощные GPU.
На сегодняшний день BatchNorm используется практически везде. Вы можете избавиться от него в коде, если хотите оценить статью на 100%, но вы можете не дожить до момента, когда сеть сойдется.
Что касается графических процессоров, в статье говорится:
To minimize the overhead and make maximum use of the GPU memory, we favor large input tiles over a large batch size and hence reduce the batch to a single image
Они использовали GPU с 6 ГБ RAM, но в настоящее время у GPU больше памяти, для размещения изображений в одном batch’e. Текущий batch равный трем, работает для графического процессора в GPU с 8 гб RAM. Если у вас нет такой видеокарты, попробуйте уменьшить batch до 2 или 1.
Что касается методов augmentations(то есть искажения исходного изображения по какому либо паттерну), рассматриваемых в статье, мы будем использовать отличные от описываемых в статье, поскольку наши изображения сильно отличаются от биомедицинских изображений.
Теперь давайте начнем с самого начала, проектируя архитектуру нейронной сети:
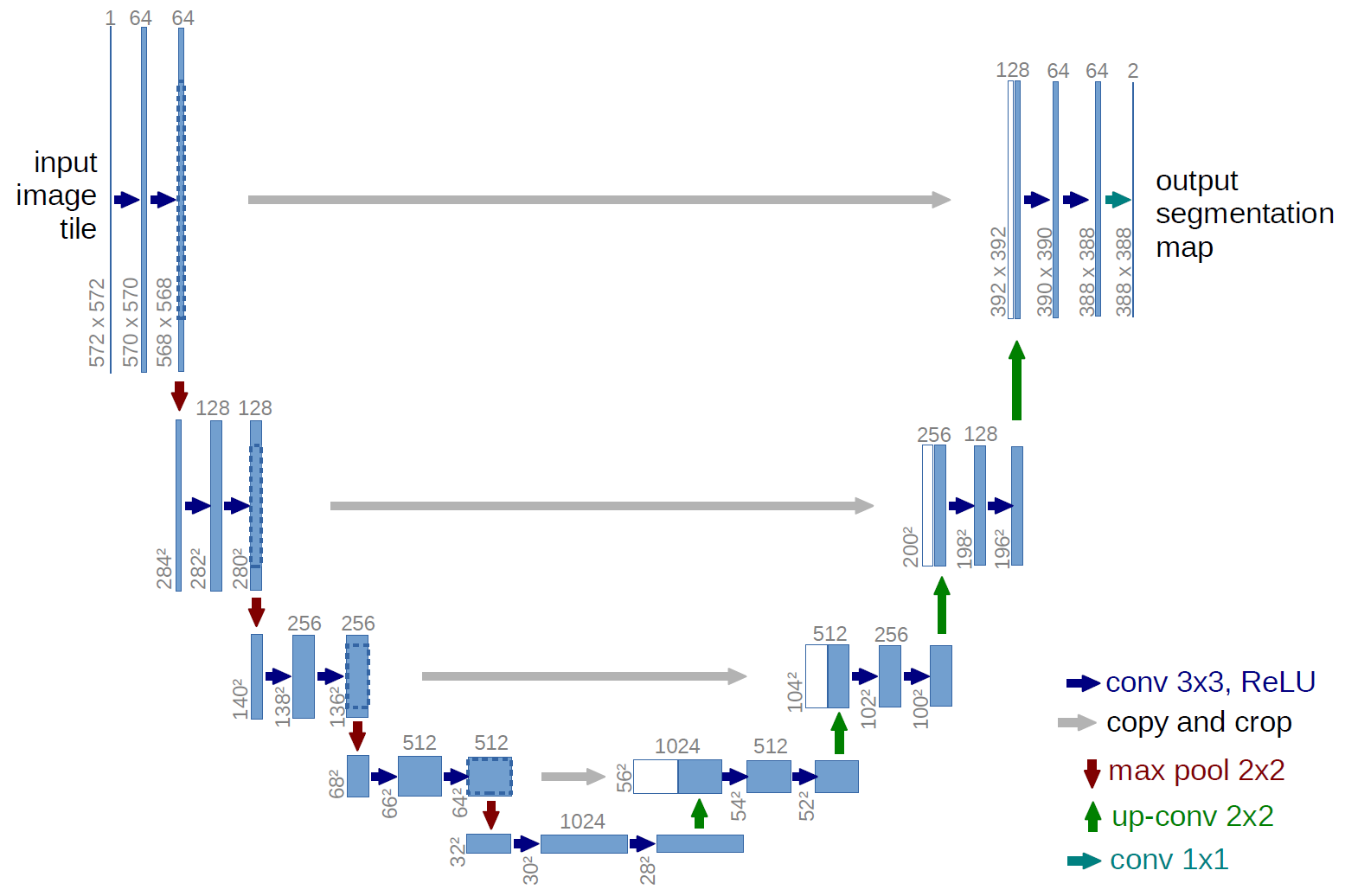
Вот как выглядит Unet. Вы можете найти эквивалентную реализацию Pytorch в модуле nn.unet_origin.py.
Все классы в этом файле имеют как минимум 2 метода:
- __init__() где мы будем инициализировать наши уровни нейронной сети;
- forward() который является методом, называемым, когда нейронная сеть получает вход.
Давайте рассмотрим детали реализации:
- ConvBnRelu - это блок, содержащий операции Conv2D, BatchNorm и Relu. Вместо того, чтобы набирать их 3 для каждого стека кодировщика (группа операций вниз) и стеков декодера (группа операций вверх), мы группируем их в этот объект и повторно используем его по мере необходимости.
- StackEncoder инкапсулирует весь «стек» операций вниз, включая операции ConvBnRelu и MaxPool, как показано ниже:

Мы отслеживаем вывод последней операции ConvBnRelu в x_trace и возвращаем ее, потому что мы будем конкатенировать этот вывод с помощью стеков декодера.
- StackDecoder - это то же самое, что и StackEncoder, но для операций декодирования, окруженных ниже красным:
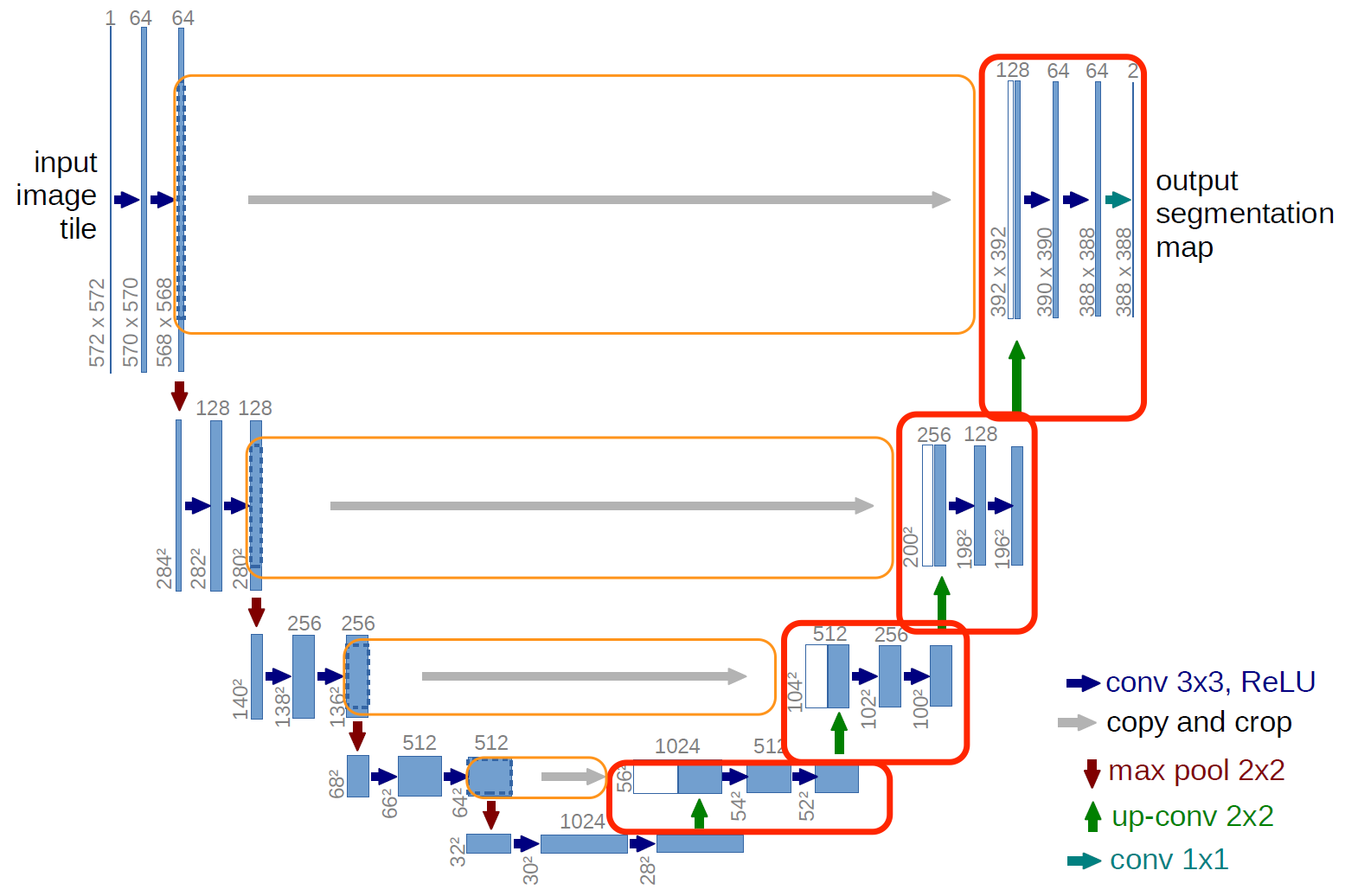
Обратите внимание, что он учитывает операцию обрезки / конкатенации (окруженную оранжевым), передавая в down_tensor, который является не чем иным, как тензором x_trace, возвращаемым нашим StackEncoder.
- UNetOriginal - это место, где происходит волшебство. Это наша нейронная сеть, которая будет собирать все маленькие кирпичики, представленные выше. Методы init и forward действительно сложны, они добавляют кучу StackEncoder, центральной части и под конец несколько StackDecoder. Затем мы получаем вывод StackDecoder, добавляем к нему свертку 1x1 в соответствии со статьей, но вместо того, чтобы определять два фильтра в качестве вывода, мы определяем только 1, который фактически будет нашим прогнозом маски в оттенках серого. Далее мы «сжимаем» наш вывод, чтобы удалить размер канала (всего 1, поэтому нам не нужно его хранить).
Если вы хотите понять больше деталей каждого блока, поместите контрольную точку отладки в метод forward каждого класса, чтобы подробно просмотреть объекты. Вы также можете распечатать форму ваших тензоров вывода между слоями, выполнив печать (x.size()).
Тренировка нейронной сети
- Функция потерь
Теперь к реальному миру. Согласно статье:
The energy function is computed by a pixel-wise soft-max over the final feature map combined with the cross-entropy loss function.
Дело в том, что в нашем случае мы хотим использовать dice coefficient как функцию потерь вместо того, что они называют «энергетической функцией», так как это показатель, используемый в соревновании Kaggle, который определяется:
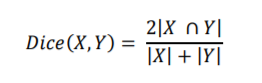
X является нашим предсказанием и Y - правильно размеченной маской на текущем объекте. |X| означает мощность множества X (количество элементов в этом множестве) и ∩ для пересечения между X и Y.
Код для dice coefficient можно найти в nn.losses.SoftDiceLoss.
class SoftDiceLoss(nn.Module): def __init__(self, weight=None, size_average=True): super(SoftDiceLoss, self).__init__() def forward(self, logits, targets): smooth =1 num = targets.size(0) probs = F.sigmoid(logits) m1 = probs.view(num, -1) m2 = targets.view(num, -1) intersection = (m1 * m2) score =2. * (intersection.sum(1) + smooth) / (m1.sum(1) + m2.sum(1) + smooth) score =1 - score.sum() / num return score
Причина, по которой пересечение реализуется как умножение, и мощность в виде sum() по axis 1 (сумма из трех каналов) заключается в том, что предсказания и цель являются one-hot encoded векторами.
Например, предположим, что предсказание на пикселе (0, 0) равно 0,567, а цель равна 1, получаем 0,567 * 1 = 0,567. Если цель равна 0, мы получаем 0 в этой позиции пикселя.
Мы также использовали плавный коэффициент 1 для обратного распространения. Если предсказание является жестким порогом, равным 0 и 1, трудно обратно распространять dice loss.
Затем мы сравним dice loss с кросс-энтропией, чтобы получить нашу функцию полной потери, которую вы можете найти в методе _criterion из nn.Classifier.CarvanaClassifier. Согласно оригинальной статье они также используют weight map в функции потери кросс-энтропии, чтобы придать некоторым пикселям большее ошибки во время тренировки. В нашем случае нам не нужна такая вещь, поэтому мы просто используем кросс-энтропию без какого-либо weight map.
2. Оптимизатор
Здесь мы попытаемся отдать дань уважения оригинальной статье, используя оптимизатор SGD и momentum 0,99. Оптимизатор можно найти в основном методе:
optimizer = optim.SGD(self.net.parameters(), lr=0.01, momentum=0.99)
Это все, что нам нужно сделать для оптимизатора.
3. Augmentations
Поскольку мы имеем дело не с биомедицинскими изображениями, мы будем использовать наши собственные augmentations. Код можно найти в img.augmentation.augment_img. Там мы выполняем случайное смещение, поворот, переворот и масштабирование.
Тренировка нейронной сети
Теперь можно начать обучение. По мере прохождения каждой эпохи вы сможете визуализировать, предсказания вашей модели на валидационном наборе.
Для этого вам нужно запустить Tensorboard в папке logs с помощью команды:
tensorboard --logdir=./logs
Пример того, что вы сможете увидеть в Tensorboard после эпохи 1:

И после эпохи 50

После обучения на более 50 эпохах мы получаем попиксельную точность около 95-96%. Это намного лучше, чем наша первая эпоха, но это качество все еще неудовлетворительно, если хотим автоматизировать задачу сегментации изображений.
Но в начале статьи была заявленно качество модели более 99%? Но здесь мы смогли получить чуть более 95%? И по этой причине позвольте мне сказать вам кое-что:

Теперь мы будем использовать специальный Unet, который вы можете найти в nn.unet.UNet1024. Не будем вдаваться в подробности реализации этой архитектуры, поскольку она очень похожа на наш оригинальный Unet с некоторыми изменениями. Все, что вам нужно сделать, это внести в файл main.py несколько изменений:
input_img_resize = (572, 572) output_img_resize = (388, 388)К
input_img_resize = (1024, 1024) output_img_resize = (1024, 1024)
И
net = unet_origin.UNetOriginal((3, *input_img_resize))
К
net = unet_custom.UNet1024((3, *input_img_resize))
Вы также можете изменить оптимизатор от SGD К RMSProp:
optimizer = optim.SGD(self.net.parameters(), lr=0.01, momentum=0.99)
К
optimizer = optim.RMSprop(self.net.parameters(), lr=0.0002)
Затем запустите тренировку снова на 50 эпох и batch size 2 (или уменьшите ее до 1, если у вас недостаточно RAM видеокарты).
Эта новая архитектура использует входы с более высоким разрешением, что позволяет Unet выучить больше представлений.
Например, вот как выглядит эпоха 24 после этих изменений:

При точности по 0,995 пикселя он выглядит намного лучше, не так ли? Конечно дальше, вы можете попытаться настроить улучшить модель самостоятельно, чтобы достичь еще лучшего качества, изменив оптимизатор/эпоху/архитектуру.
Ссылки на использованные материалы:
- https://arxiv.org/abs/1505.04597
- https://tuatini.me/practical-image-segmentation-with-unet/
- https://github.com/EKami/carvana-challenge/tree/original_unet/


Комментарии
Отправить комментарий